
Série Especial Sobre Inteligência Artificial para Designers & Product Managers AQUI.
Claude Code Product OS:
O Guia Definitivo para Criar Agentes de IA que Aumentam a Produtividade de Designers e Product Managers
Como montar um assistente de IA que faz por você as tarefas operacionais do dia a dia (pesquisa, documentação, análise, especificação) enquanto você ganha tempo para o que realmente importa: estratégia, produto e usuário.
TL;DR
Se você é designer, PM, growth ou está empreendendo, dá para construir um agente de IA no Claude Code que vira o seu assistente de trabalho de verdade. Ele faz desk research enquanto você almoça, gera PRDs, monta relatórios, cria especificações e já entrega tudo organizado dentro das ferramentas que você usa (Google Drive, Notion, Linear).
A ideia central é simples: automatizar o operacional para você focar no estratégico. Neste guia eu mostro a estrutura completa, do conceito de harness até versionamento, segurança e memória persistente. Os pontos que você precisa levar daqui:
O que você vai encontrar neste guia:
- O que é (e por que isso muda o seu dia a dia)
- O que diferencia um agente de um prompt
- Agente vs. automação tradicional (n8n, Zapier)
- Objetivo (gerar tempo para focar na estratégia)
- Exemplos de agentes
- Principais Características
- Como Construir: harness, prompt system vs. harness, arquitetura do projeto, modelos, conectores, skills, commands, hooks, rotinas, hooks vs. rotinas e como testar antes de produção
- A Interface do Agente: Claude Code, visualização de arquivos, chaves e autenticação, versionamento, o que versionar, segurança de chaves, colaboração e memória persistente
- Exemplos de Uso de Agentes
- Conexões e Tools Úteis
- Erros Comuns de Quem Começa com Agentes
- Como Medir se o Agente Está Funcionando Bem
- Checklist para Criação de um Agente
No nosso Curso de IA para UX & PM da PunkMetrics, eu explico todo esse processo em vídeos passo a passo, entrego todos os prompts prontos, o board do Figma com o fluxo completo e o repositório do GitHub com a estrutura toda. Você copia, adapta e sai usando no mesmo dia.
O que é (e por que isso muda o seu dia a dia)
Um agente de IA, na prática, é o seu assistente de trabalho. Não é um chatbot que responde perguntas soltas. É uma estrutura que executa tarefas cotidianas da sua área de atuação de forma autônoma, da pesquisa até a entrega do documento final, organizada e salva onde você trabalha.
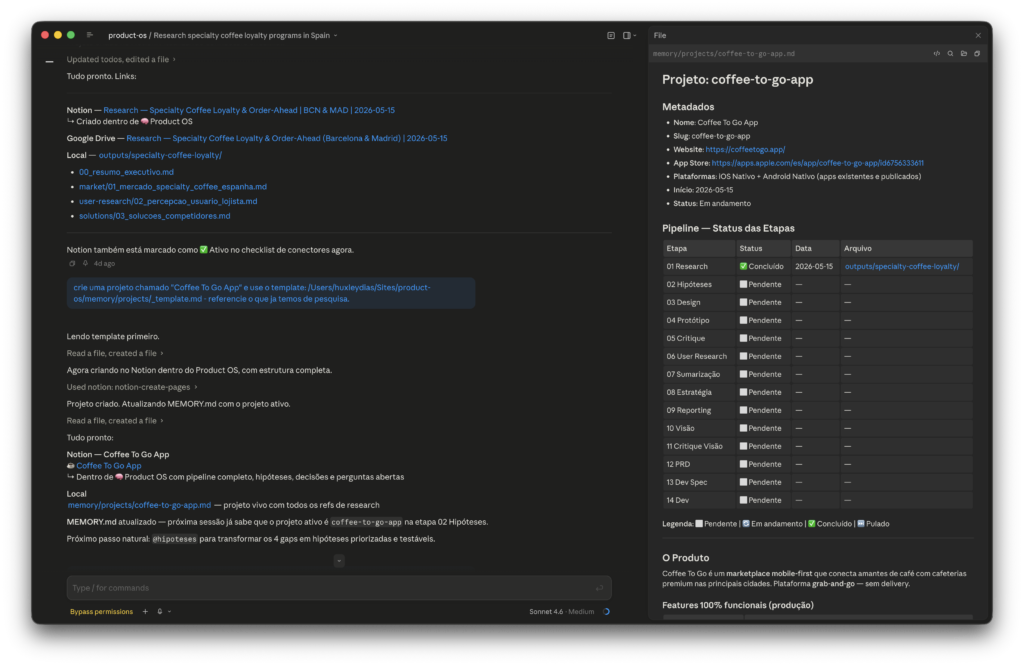
Deixa eu te dar um exemplo real do que isso significa. Eu pedi para o meu agente fazer uma pesquisa de mercado dentro do ramo de soluções tecnológicas para cafeterias de especialidade. Defini a região, defini os critérios que eu queria observar, e ele rodou tudo sozinho. Gerou o resumo executivo, a percepção do usuário e do lojista, o mapeamento de soluções e competidores. Conectou no Google Drive, jogou um arquivo no Notion, gerou um Google Docs no Drive com a mesma pesquisa completa. E o melhor: ele fez isso enquanto eu almoçava. Deixei rodando numa sessão remota e fui acompanhando pelo app do Claude no celular.
Por que ele conseguiu fazer isso? Porque eu dei a ele a capacidade de pesquisar dentro de um formato que eu instruí, seguindo padrões que eu defini, e toda vez que ele gera um output ele organiza do jeito que eu mandei, já conectado com as plataformas do meu dia a dia. É isso que você vai aprender a construir aqui.
O que diferencia um agente de um prompt
Essa é a confusão número um, então vamos resolver logo. Quando você manda uma mensagem para um modelo de IA, você recebe uma resposta e acabou. Cada conversa começa do zero. Você fica repetindo contexto, explicando quem você é, o que faz, em que projeto está.
Um agente é diferente. Ele tem contexto persistente (ele sabe quem você é e no que está trabalhando), tem memória (ele acumula aprendizado entre sessões), tem ações encadeadas (ele faz pesquisa, compila, gera documento e salva, tudo num fluxo só) e tem ferramentas conectadas (ele acessa seu Drive, seu Notion, faz scraping da web). Quando você junta tudo isso, deixa de ter um chat e passa a ter um colaborador.
Agente vs. automação tradicional (n8n, Zapier)
Vale também separar agente de automação clássica. Ferramentas como n8n e Zapier são ótimas para fluxos determinísticos, aquele “se acontece A, faz B”. São previsíveis e baratas quando a tarefa é sempre igual.
Um agente entra quando a tarefa exige interpretação, julgamento e adaptação. Uma desk research nunca é igual à anterior, um PRD precisa raciocinar sobre contexto, uma crítica de protótipo depende de avaliar o que está na tela. Para isso você quer um agente. A regra de bolso: se a tarefa é mecânica e idêntica todo dia, automação tradicional resolve. Se ela exige pensar, é agente.
Objetivo (nunca perda de vista)
O objetivo aqui, e eu quero que você tenha isso sempre em mente, é ganhar velocidade nas tarefas operacionais para liberar tempo e energia para o que é estratégico. Toda a parte de pesquisa, documentação, análise, especificação e relatório, a gente automatiza boa parte. O que sobra de tempo você investe no aprofundamento do negócio, nas necessidades reais do usuário, nas decisões que só você pode tomar. Velocidade no operacional para sobrar craft no que importa.
Para quem é esse guia
Esse guia é para quem trabalha com gestão de produto, com design, com growth, ou para quem está empreendendo e ocupa posições parecidas. A estrutura que vou apresentar serve de exemplo, ela tenta se aproximar ao máximo do fluxo de trabalho dessas pessoas.
E já adianto uma coisa importante: ela não vai ser perfeita e talvez não reflita exatamente a sua realidade. Tudo bem. Use isso como ponto de partida e customize do jeito que fizer mais sentido para você. Com certeza boa parte vai servir e vai faltar uma pecinha ou outra que você acrescenta à sua maneira. O importante é entender a essência.
Exemplos de agentes
Para um projeto que sirva como base inicial, tentie replicar etapas cotidianas do processo de produto, não de forma exautiva, mas que cubra a maior parte dos casos tradicionais de etapas do fluxo de produto:
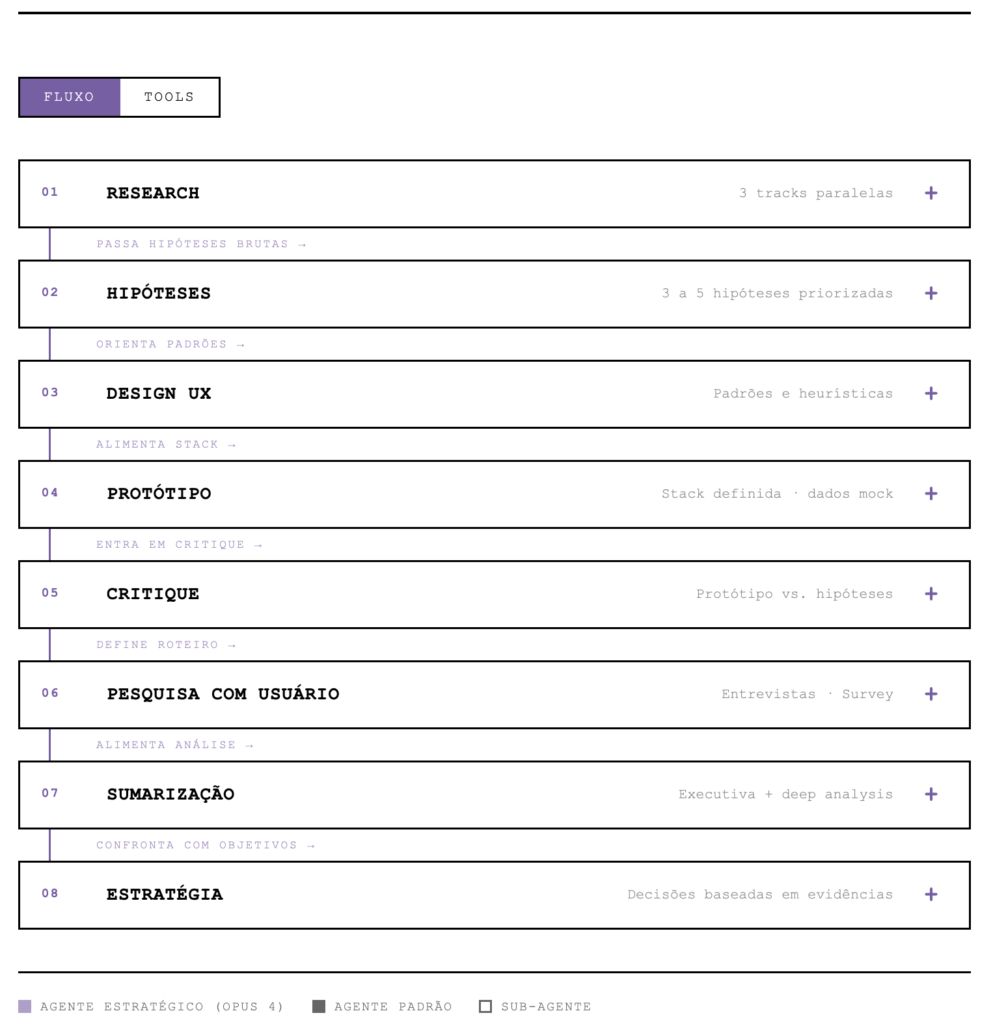
- Research, que no meu caso eu separei em três pilares: mercado, competidores e visão do usuário.
- Hipóteses, para transformar achados de pesquisa em hipóteses explícitas.
- Design, que faz o design brief dos fluxos.
- Protótipo, que gera protótipos com React e Tailwind.
- Crítica de protótipo, que olha o que foi gerado com olhar crítico.
- User research, que monta roteiro e survey baseados no protótipo e na pesquisa anterior.
- Sumarização, que consolida o resultado das pesquisas.
- Estratégia, que aqui já usa um modelo mais potente.
- Relatório e apresentação, que pega tudo que foi construído e sintetiza num material executivo.
- Visão e crítica da visão, para construir e estressar a visão do produto ou da feature.
- PRD, o documento de requisitos do produto.
- Especificações técnicas, que transformam o PRD em requisitos para desenvolvimento.
Quando todos esses agentes estão funcionando, passar de uma etapa para a outra fica muito fácil, porque o seu assistente tem contexto de tudo.
Principais Características
Antes de construir, entenda o que faz um agente valer a pena. Esses são os sinais de que uma tarefa é boa candidata a virar agente:
- Processos repetitivos. Tarefas que você faz toda semana com a mesma estrutura. É aí que a automação rende.
- Output padronizado. O agente sempre entrega no mesmo formato, pronto para usar. Você instrui uma vez, ele repete sempre.
- Multi-steps. Ele executa sequências encadeadas (pesquisa, compila, gera, salva), não uma resposta isolada.
- Integração entre plataformas. Ele conecta ferramentas diferentes num fluxo único. Pesquisa na web, salva no Drive, registra no Notion.
- Colaboração e versionamento. O agente pode ser compartilhado e evoluído pelo time todo, usando o mesmo padrão.
- Multi-agent, skills e tools. A combinação de agentes especializados, capacidades específicas e conectores externos é o que dá robustez ao sistema.
Como Construir
Agora a parte prática. Eu vou te dar o caminho completo, e no fim eu te mostro o atalho que economiza horas.
Conceito de harness
Pensa no harness como o “container” que define como o agente opera: as regras dele, o tom, o escopo de atuação, os princípios fundamentais. No nosso caso, esse comportamento mora num arquivo central. É ali que está escrito, por exemplo, que ele é um assistente de gestão de produtos especializado, que guia o PM por todo o ciclo de discovery, com princípios como “evidência primeiro” (toda decisão ancorada em dados e pesquisa), “hipóteses explícitas”, “sem autoconfirmação” e “olhar crítico”. Você pode adicionar os princípios que quiser, tipo “não decida por mim”, “não tome ações sem permissão”, “não faça suposições implícitas”.
Prompt system vs. harness
Muita gente confunde os dois. O system prompt é a instrução base, o “quem você é”. O harness é a estrutura completa em volta disso: o system prompt mais os arquivos de contexto, a memória, as regras de cada agente, os templates. Um bom system prompt é necessário, mas é o harness bem montado que faz o agente ser consistente de verdade.
Arquitetura do projeto (pastas, agentes)
Aqui tem um esclarecimento que evita muita dor de cabeça. O seu agente vive num diretório próprio, e esse diretório é o do seu assistente de trabalho, não o do seu produto. Se você já faz vibe coding e tem o código de um projeto, o agente não deve morar lá dentro. É uma estrutura independente. Recomendo fortemente que seja outra pasta, outro ambiente.
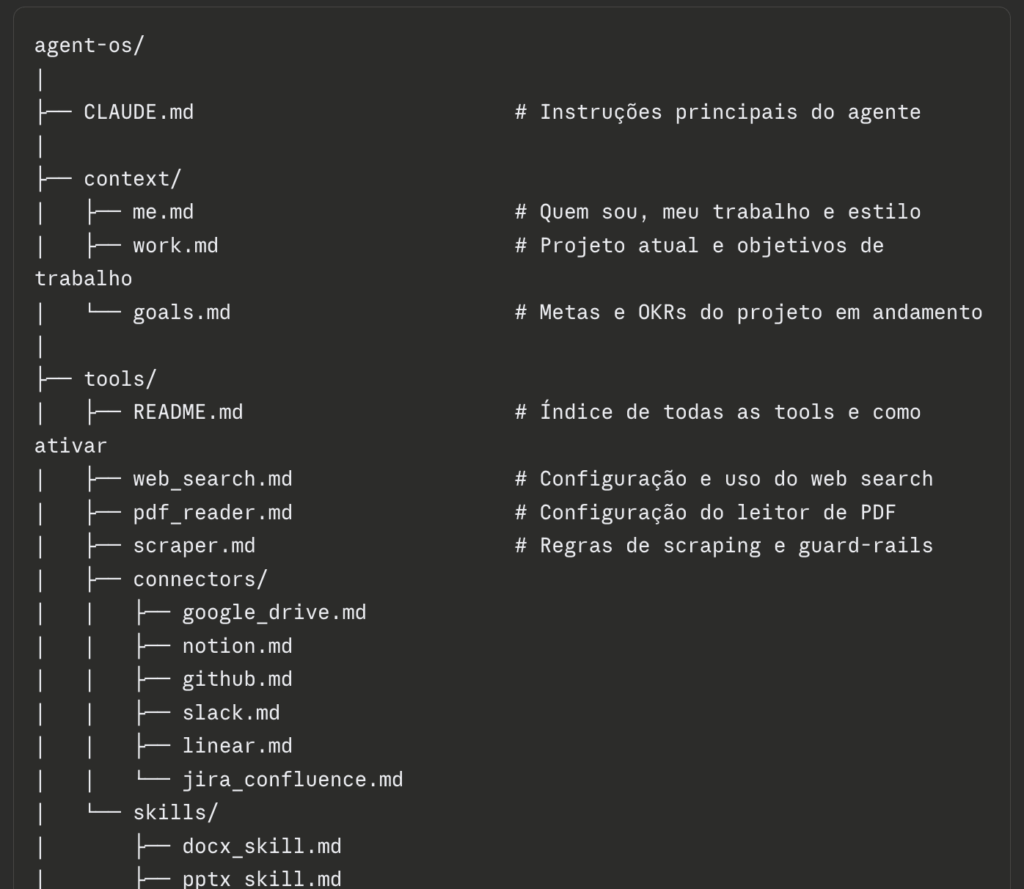
Dentro desse diretório, a estrutura que eu montei segue um fluxo de construção de produto, da pesquisa até as specs de desenvolvimento. Tem a pasta de agentes, a pasta de contexto, a pasta de memória, a pasta de projetos (que começa como template e vai sendo preenchida), a pasta de outputs (onde ele salva o que constrói), a de templates, a de tools e a de secrets. E lembre: a intenção não é te ensinar método de produto. O foco é aprender a construir o agente. Se a sequência que eu uso não combina com o seu jeito de fazer produto, sem problema, foque na estrutura.
No Curso de IA para UX & PM da PunkMetrics eu disponibilizo o board do Figma com esse fluxo inteiro mapeado, etapa por etapa, com as notas de cada uma. É só acessar o link, solicitar acesso e eu libero. Você usa o board como guia de referência tanto na criação quanto depois, quando quiser montar novos agentes.
Modelos
Esse ponto é importante: você faz gestão de modelos. Para tarefas mais pesadas e específicas, como estratégia, você pede um modelo mais robusto. Para tarefas cotidianas, usa um modelo do dia a dia, que também é muito potente. Cada agente pode ter o seu modelo definido. No setup eu costumo rodar com Opus para o trabalho pesado e Sonnet para o resto, e isso já dá conta com folga.
Conectores
Os conectores são o que dá superpoderes ao seu agente. É o que a gente chama de “dar braços” a ele. Sem conectores, ele pensa mas não age no seu mundo. Com eles, ele vai no seu Google Drive buscar uma planilha ou um doc, cria um arquivo novo, consulta um MCP de base de dados, lê o Figma, registra no Notion, abre um card no Linear. Vou aprofundar conectores numa seção dedicada mais abaixo, porque tem detalhe que vale a pena.
Skills – Ensinar o agente a fazer correto
Skills são as capacidades específicas que você ensina ao agente para ele executar com consistência. É o “como fazer” de uma tarefa. Por exemplo, a skill de research carrega o padrão de como pesquisar, quais critérios observar, como deixar as referências no final. Toda vez que ele faz uma pesquisa, ele segue aquela skill, e por isso o output sai sempre no mesmo nível.
Temos aqui um guia prático de como como criar skills para Claude Code.
Commands
Commands são comandos rápidos que acionam comportamentos pré-definidos sem você ter que explicar o contexto toda vez que aciona o agente. São atalhos para rotinas que você usa muito.
Hooks
Hooks são gatilhos automáticos que disparam uma ação do agente em resposta a um evento. Algo acontece, o hook dispara, o agente reage. Eles são reativos por natureza.
Rotinas
Rotinas são fluxos programados que o agente executa em intervalos ou condições que você definiu. Diferente do hook, que reage a um evento pontual, a rotina é planejada e recorrente.
Quando usar cada um (hooks vs. rotinas)
A diferença prática: use hook quando você quer uma reação imediata a um evento específico (criou um arquivo, mudou um status, chegou algo). Use rotina quando você quer algo recorrente e previsível (toda segunda de manhã, ao fim de cada sessão). Hook é reativo e pontual; rotina é programada e repetida.
Como testar um agente antes de colocar em produção
Etapa que quase todo mundo pula e depois se arrepende. Antes de confiar no agente para valer, faça um check inicial: pergunte para ele “quem é você e como você pode me ajudar”. Isso revela se ele leu todas as especificações, se carregou o contexto, se está com a personalidade certa. Faça uma verificação de quais ferramentas (conectores, MCP, CLI) ele te macesso. Depois rode uma tarefa pequena e controlada, tipo uma pesquisa pontual, e veja se ele segue os critérios que você definiu e se entrega no formato esperado. Testou nos casos simples antes de soltar nos complexos.
A Interface (onde o agente vive)
O agente precisa de uma casa. Vamos às opções e ao que faz sentido para você.
O app Claude Code como facilitador
O Claude Code é o ambiente principal onde você constrói, testa e roda o agente. Dá para usar no desktop, no terminal, dentro de um editor, e até numa sessão remota acompanhada pelo app do celular. Foi assim que eu deixei a pesquisa rodando enquanto almoçava e fui acompanhando pelo telefone.
App para visualizar e editar arquivos
Como boa parte da estrutura são arquivos Markdown, vale ter algo para visualizar e editar. Eu costumo usar o próprio editor que já tenho aberto, mas tem opções como o Antigravity e o Obsidian. O Obsidian ficou famoso com a ideia de “second brain”, conectando arquivos Markdown numa malha, mas serve perfeitamente só para você visualizar um arquivo Markdown com um tratamento visual melhor. Escolha o que for mais confortável. PS: atenção com a atualização do Antigravity, aquele layut que mostra a estrutura de pastas e o editor agora ficaram no Antigravity IDE, que deve ser baixado separadamente.
Chaves e autenticação (diferentes métodos)
Toda ferramenta que você conecta precisa de algum tipo de autenticação. A forma mais comum, inclusive na web, é o OAuth: você clica num botão, é levado para a página do serviço, autoriza e segue. Especialmente fácil quando você já tem conta naquele produto.
Mas existem outros formatos: chave de API, user secret key, public key. No terminal ou no editor, é só digitar o comando de login e escolher se quer entrar com chave de API ou com a sua assinatura. A maioria das pessoas tem o plano Pro e usa a opção de assinatura: clica, abre o navegador, autoriza a aplicação e pronto, está conectado.
E tem um detalhe que poupa muito trabalho no começo: existem duas formas de conectar. Você pode autenticar serviços direto na sua conta Claude (na nuvem) ou no nível do projeto (via MCP). Se você já tem Drive, Gmail, Linear conectados na sua conta Claude, o agente já consegue usar sem nenhuma configuração de MCP. Você pede “faça tal coisa e no final crie um arquivo no Google Drive” e ele cria, usando a sua autenticação da conta. Para encontrar isso, vá em (Configurações > Capabilities > Customize) e você chega na tela que une Skills e Conectores.
Versionamento (GitHub não é opcional)
Versionar não é um detalhe técnico, é parte da estrutura do agente. Conforme o seu agente evolui, ele vai acumulando arquivos, configurações, credenciais. Sem versionamento, você fica exposto ao acaso: perde histórico, não consegue voltar atrás, não consegue compartilhar com o time de forma consistente.
E não se preocupe: o próprio agente cuida de quase tudo aqui. Você não precisa dominar Git para isso. Mas precisa ter o projeto no GitHub, e ele precisa ser privado.
O que versionar e o que não versionar
Regra clara para não vazar nada e não poluir o repositório. As pastas descartáveis, como a de output do projeto e os arquivos temporários que o scraper gera durante a busca, vão para o .gitignore, senão você fica mandando arquivo inútil para o GitHub. Esses arquivos são descartáveis, ele usa só no momento da busca. O ideal é que ao terminar, o agente gere o documento final e salve no Google Drive, no Linear ou no Notion, a ferramenta que você preferir. Você quer versionar a estrutura do agente (configurações, skills, definições), não o lixo de processamento nem as credenciais.
Padrão de segurança para não expor chaves e APIs
Aqui mora o risco mais sério, então atenção. Se você sobe uma chave ou credencial para o GitHub e outra pessoa copia, ela vai usar a sua credencial. Se o repositório for público, piorou muito. Por isso o repositório é privado, sempre.
A solução padrão da indústria é o arquivo .env (de environment, ambiente). Ele guarda uma chave para cada serviço que você usa. Toda vez que o agente requisita um serviço, ele consulta o .env, carrega a credencial e usa, e esse arquivo nunca vai para o GitHub. É simples, é compatível com o Claude Code, é padrão de mercado. O único risco real é alguém usar a sua própria máquina física, e aí não tem o que fazer. Fora isso, você está blindado.
Um detalhe operacional: o .env é um arquivo oculto. No Mac, você exibe arquivos ocultos com Command + Shift + Ponto. No Windows, precisa habilitar a exibição de arquivos ocultos na pasta. Tudo que começa com ponto (pastas e arquivos) fica oculto para o usuário padrão. Eu deixo também um protocolo de dupla verificação para garantir que você não está deixando nada passar.
No Curso de IA para UX & PM da PunkMetrics o repositório do GitHub já vem montado com o .gitignore configurado e o protocolo de segurança pronto, então você herda tudo isso sem ter que pensar do zero.
Colaboração e padronização
Esse é um dos maiores ganhos quando você trabalha em time. Se você coloca o agente no GitHub (privado) e mantém ele atualizado, todas as pessoas do time passam a usar o mesmo sistema: mesmo padrão de entrada, mesmo processo, mesmas tools, mesmo output. Você para de ter cada pessoa fazendo research de um jeito, PRD de outro. O agente vira o denominador comum de qualidade do time.
Sistema de memória persistente
Esse ponto é extremamente importante, presta atenção. Você já deve ter passado por isso: começa um trabalho com a IA e ela fica te fazendo perguntas básicas que você já respondeu mil vezes, porque ela simplesmente não lembra. A memória persistente resolve isso.
Como funciona: o agente tem uma instrução de leitura obrigatória, a cada sessão, de um arquivo de memória com o contexto atual do projeto, os objetivos e os próximos passos. Essa memória tem regras que vão se ajustando e se acumulando. Por exemplo, você fala uma vez “toda vez que criar um arquivo no Google Drive, compartilhe com o e-mail XPTO”, e ele grava isso para sempre (esse é um caso real que eu uso muito). Ele tem memória específica por projeto: você declara “estou trabalhando nesse projeto” e ele cria uma memória dedicada baseada num template. Ele escreve nessa memória durante a sessão, ao final de cada sessão e quando uma correção é feita.
Eu acrescentei ainda um arquivo de glossário, com os termos do domínio em que você trabalha. Se você é de finanças, tem terminologia que só existe nesse mundo; se é de educação, tem outra. Alimentar esse glossário deixa o agente cada vez mais espertinho.
Uma observação honesta: hoje ainda não existe um sistema de memória perfeito. Esse aqui funciona e é eficiente para a maioria dos casos, mas com o tempo os arquivos podem crescer e a memória se degradar. Então peça para ele fazer uma limpeza de tempos em tempos, removendo o que não está mais em uso. É o melhor que a gente tem hoje e funciona muito bem na prática.
Exemplos de Uso de Agentes
Casos práticos para você ver o potencial:
- Desk research. Você dá o direcional e ele explora plataformas, busca conteúdo e reports, compila tudo e deixa as referências no final para você conferir de onde veio cada informação. Foi o primeiro caso que a gente colocou para rodar.
- Breakdown de documentação. Leitura e síntese de documentos longos em formatos acionáveis.
- Criação de campanha de ads (integrado Google Ads e Meta Ads). Do briefing à publicação, com dados reais das contas.
- Geração de PRD. O documento de requisitos do produto, criado a partir do contexto e dos objetivos que o agente já carrega.
- Geração de Spec Driven. Especificações técnicas geradas com base nos critérios definidos pelo time.
- Casos de uso para times de produto e design. Mapeamento de eventos, síntese de research, geração de OKRs e por aí vai.
Todos esses casos estão demonstrados em vídeo, com os prompts prontos, no Curso de IA para UX & PM da PunkMetrics.
Agentes de Prototipação
Vale separar um tipo específico de agente: o de prototipação. Ele é focado em velocidade e experimentação visual. Não tem banco de dados, usa mock data e segue critérios de design para gerar protótipos de baixa e média fidelidade. É o agente que faz protótipo com React e Tailwind, e tem um companheiro que critica esse protótipo com olhar de design.
A diferença para os agentes de codificação do produto final é grande. O agente que codifica o produto de verdade tem outras preocupações: definição de stack, arquitetura da aplicação, banco de dados, dependências, design system, variáveis de ambiente, versionamento, testes e deploy. Isso é outra história, e a parte de desenvolvimento da aplicação não mora dentro desse assistente, ela vai para outro diretório, outro projeto. Vou cobrir esse tema num próximo artigo.
Conexões e Tools Úteis
Um mapa rápido para você não se perder na hora de dar braços ao agente.
- MCPs. O Model Context Protocol é o padrão aberto para conectar agentes a sistemas externos. É via MCP que você pluga ferramentas no nível do projeto.
- Skills. Capacidades pré-construídas que aceleram a criação de novos agentes.
- Plugins. Extensões que ampliam o que o agente faz nativamente.
- Tools. As ferramentas específicas que o agente aciona durante uma tarefa.
Vale entender uma diferença prática que confunde muita gente. O Claude Code, nativamente, já faz fetch: você aponta um domínio e ele busca a informação. Mas ele não renderiza JavaScript, não faz bypass de antibot, traz texto bruto e HTML, não faz crawler de várias páginas e a confiabilidade cai em sites modernos cheios de proteção. Por isso, para a primeira funcionalidade do assistente, que é a desk research, eu recomendo conectar o Firecrawl, uma ferramenta dedicada a scraping. Ela renderiza JavaScript completo, faz bypass de bot, navega por várias páginas, traz o conteúdo em Markdown ou JSON já estruturado com IA, e aumenta muito a confiabilidade.
A instalação é simples: você cria a conta no Firecrawl, pega a chave de API no dashboard, e pede para o próprio Claude Code te ajudar a instalar. Ele cria o arquivo de configuração de MCP, lê a chave do seu .env, e está pronto. Lembrando que, depois de qualquer configuração nova, você precisa reiniciar a sessão do Claude para ele carregar o novo conector. Isso é uma pegadinha clássica: o conector só aparece se a sessão foi iniciada depois de você conectá-lo. Se adicionou depois, fecha e abre de novo.
E uma recomendação de organização que vale ouro: deixe claro que o seu projeto deve usar apenas os conectores do projeto. Se você deixar o agente puxar todos os conectores da sua conta pessoal, ele pode carregar conexões demais, gastar um monte de tokens e fazer coisas fora do escopo. Eu separo: o projeto usa um e-mail específico de trabalho, e a minha conta pessoal fica de fora daquele contexto. Isso evita aquele erro chato de você criar um arquivo no Drive com uma conta enquanto o agente está autenticado em outra.
Erros Comuns de Quem Começa com Agentes
Os tropeços mais frequentes, para você já começar evitando:
- Contexto genérico demais. Agente sem contexto específico entrega resposta rasa. Alimente o perfil, os objetivos, o projeto.
- Sem memória. Sem memória persistente, você reexplica tudo toda sessão e o agente nunca fica esperto.
- Output indefinido. Se você não padroniza o formato de saída, cada entrega vem diferente e você perde a vantagem.
- Misturar o agente com o código do produto. Eles são estruturas independentes. Não junte.
- Esquecer o .gitignore e vazar chave. O erro mais caro. Repositório privado e .env fora do versionamento, sempre.
- Achar que conector novo já funciona sem reiniciar. Reinicie a sessão depois de cada configuração.
Dicas de Frameworks Populares
Conforme você avança, vai querer acrescentar frameworks ao seu ecossistema, principalmente na parte de implementação. Alguns que vale acompanhar:
- GStack (Garry Tan’s exact Claude Code setup: 23 opinionated tools that serve as CEO, Designer, Eng Manager, Release Manager, Doc Engineer, and QA)
- GSD (A light-weight and powerful meta-prompting, context engineering and spec-driven development system for Claude Code by TÂCHES.)
- Superpower (An agentic skills framework & software development methodology that works.)
Eu uso esses frameworks na etapa de desenvolvimento, que é justamente o conteúdo do próximo artigo.
Como Medir se o Agente Está Funcionando Bem
Construir é só metade do trabalho. O agente precisa ser avaliado de forma contínua. Olhe para a consistência do output (ele entrega sempre no mesmo nível?), a taxa de erro (com que frequência ele erra ou alucina?) e o tempo economizado (quanto da sua semana ele realmente liberou?). Quando algum desses indicadores piora, é sinal de que a memória precisa de limpeza, o contexto precisa de atualização ou alguma instrução precisa de ajuste. Trate o agente como um sistema vivo, não como algo que você monta e esquece.
Checklist para Criação de um Agente
Use isso como sua lista de conferência antes de dar o agente por pronto:
- Criei um diretório próprio para o assistente, separado do código do produto.
- Defini o harness: personalidade, princípios e escopo no arquivo central.
- Montei a estrutura de pastas (agentes, contexto, memória, projetos, outputs, templates, tools, secrets).
- Criei os agentes especializados que cobrem o meu fluxo.
- Defini o modelo de cada agente (robusto para tarefa pesada, cotidiano para o resto).
- Escrevi as skills com os padrões de execução de cada tarefa.
- Conectei as ferramentas do dia a dia (Drive, Notion, Linear) e o Firecrawl para research.
- Configurei a autenticação e organizei as chaves no .env.
- Preenchi o contexto: perfil, trabalho, objetivos e metas.
- Ativei o sistema de memória persistente e o glossário do domínio.
- Subi o projeto para um repositório GitHub privado.
- Configurei o .gitignore para outputs descartáveis e o .env.
- Rodei o protocolo de segurança de dupla verificação de chaves.
- Fiz o check inicial (“quem é você e como pode me ajudar”).
- Testei com uma tarefa pequena antes de soltar nas complexas.
- Defini onde os outputs finais são salvos (Drive, Notion ou Linear, Jira, etc).
Quer ajuda para fazer isso com meu apoio, passo a passo?
Esse guia te deu o mapa completo. Mas se você quer atravessar o caminho sem tropeçar, é exatamente isso que a gente faz no Curso de IA para UX & PM da PunkMetrics.
Lá eu explico todo esse processo em vídeos detalhados, do zero até o agente rodando. Você recebe todos os prompts prontos (incluindo o MetaPrompt que cria a estrutura inteira de pastas, agentes e skills para você), o board do Figma com o fluxo de produto mapeado etapa por etapa, e o repositório do GitHub com a estrutura completa, o .gitignore e o protocolo de segurança já configurados.
Você não precisa saber programar. Esse sempre foi o nosso compromisso: facilitar ao máximo para pessoas não técnicas. Você copia, adapta para o seu contexto e começa a usar o seu assistente no mesmo dia, ganhando tempo para fazer o que realmente move o seu produto.
👉 Conheça o Curso de IA para UX & PM da PunkMetrics e construa o seu Product OS.
Links Úteis:



{kind=link}